The performance of generative adversarial networks (GANs) heavily deteriorates given a limited amount of training data. This is mainly because the discriminator is memorizing the exact training set. To combat it, we propose Differentiable Augmentation (DiffAugment), a simple method that improves the data efficiency of GANs by imposing various types of differentiable augmentations on both real and fake samples. Previous attempts to directly augment the training data manipulate the distribution of real images, yielding little benefit; DiffAugment enables us to adopt the differentiable augmentation for the generated samples, effectively stabilizes training, and leads to better convergence. Experiments demonstrate consistent gains of our method over a variety of GAN architectures and loss functions for both unconditional and class-conditional generation. With DiffAugment, we achieve a state-of-the-art FID of 6.80 with an IS of 100.8 on ImageNet 128x128 and 2-4x reductions of FID given 1,000 images on FFHQ and LSUN. Furthermore, with only 20% training data, we can match the top performance on CIFAR-10 and CIFAR-100. Finally, our method can generate high-fidelity images using only 100 images without pre-training, while being on par with existing transfer learning algorithms. Code is available at https://github.com/mit-han-lab/data-efficient-gans.

Generated with 100 images of Obama, grumpy cats, pandas, the Bridge of Sighs, the Medici Fountain, the Temple of Heaven, without pre-training.
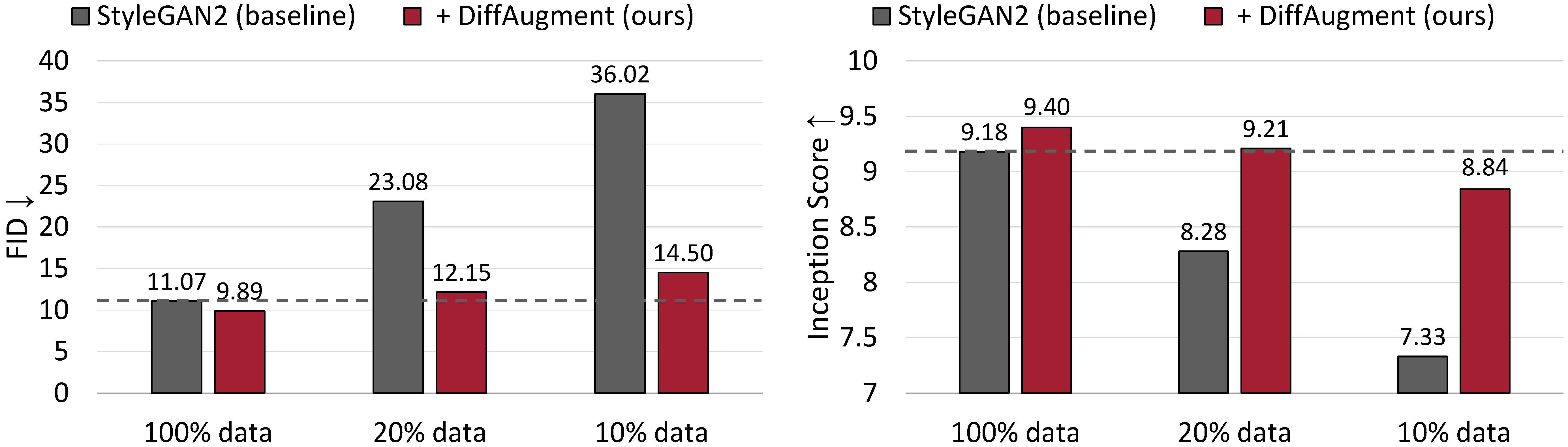
With DiffAugment, we are able to roughly match StyleGAN2's FID and outperform its Inception Score (IS) using only 20% training data on CIFAR-10.

Overview of DiffAugment for updating D (left) and G (right). DiffAugment applies the augmentation T to both the real sample x and the generated output G(z). When we update G, gradients need to be back-propagated through T (iii), which requires T to be differentiable w.r.t. the input.




@inproceedings{zhao2020diffaugment,
title={Differentiable Augmentation for Data-Efficient GAN Training},
author={Zhao, Shengyu and Liu, Zhijian and Lin, Ji and Zhu, Jun-Yan and Han, Song},
booktitle={Conference on Neural Information Processing Systems (NeurIPS)},
year={2020}
}



